Databases 2.0 – Cassandra
- 8 minutes read - 1677 words
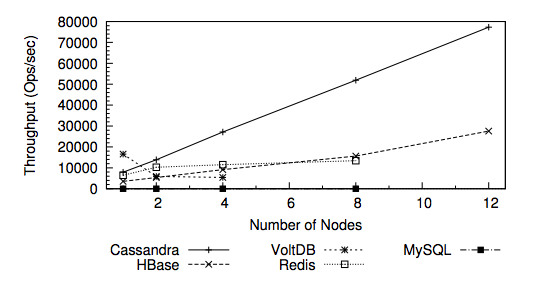
Ik ben bezig met het opzetten van een eigen weerstation. Tijdens het opzetten kwam ik er achter, dat je een grote hoeveelheden data wilt opslaan (temperatuur, luchtvochtigheid, wind-snelheid, en meer…) en dat elke 10 seconden opnieuw. In dit artikel ga ik Cassandra gebruiken en leg ik uit waarom het efficiënter is vergeleken met MySQL of andere relationele databases.
Wat is er mis met MySQL?
Veel mensen kiezen voor database systemen waar men bekend mee zijn, bekende voorbeelden zijn: MySQL & PostgreSQL. Dit soort databases werken goed met wat kleinere websites of een simpele applicatie. Zo gebruikt WordPress een MySQL database. Echter vaak is het goed om eens verder te kijken. In het geval van een weerstation betreft het heel veel data (Big Data) over de tijd (ook wel timeseries genoemd). Relationele databases (RDBMS) staan er om bekend om slecht te schalen en zijn niet decentraal. Dit houdt in dat als de database groeit in grootte, dat deze database systemen het op ten duurt veel te verduren krijgt. MySQL wordt traag en extra servers erbij zetten, dat is ook niet de sterkte kant van MySQL. Nu komen “Non-SQL” databases erbij kijken. Dit is een benaming voor database systemen die juist NIET gebaseerd zijn op relationele databases.
Non-SQL

Non-SQL databases zijn databases die niet vast zitten aan kolom relaties tussen andere tabellen. In plaats daarvan wordt de data opgeslagen in de dezelfde tabel, waardoor de relatie tussen tabellen minder is of verdwijnt. Dit heeft als voordeel dat zulk soort systemen veel beter grotere hoeveelheden data aankunnen. En de data is hierdoor tevens goed te verdelen in een database cluster netwerk. Er bestaan verschillende non-SQL databases database. Bekende zijn Cassandra, MongoDB en Hbase.
Het wisselen van een relationele database naar een non-SQL database zoals Cassandra, vergt wel een andere denkwijze. In Cassandra bestaat er “partition keys” om maar wat te noemen. Deze key is en veld in je tabel (net als een “id” veld in MySQL) en via deze partition key weet Cassandra WAAR de data staat in je database cluster (welke node/server). Kortom, bij het ontwerpen van een Cassandra keyspace (ook wel database) en tables moet je anders naar de data gaan kijken. Het werkt immers anders dan een relationele database.
Gelukkig kent Cassandra een query taal, genaamd CQL (Cassandra Query Language), wat erg lijkt op SQL. Dit maakt het werken met Cassandra gelukkig een stuk eenvoudiger, mits je SQL al kende.
Cassandra

Cassandra Apache is een schaalbare, hoge beschikbaarheid een zeer goed performances database management systeem. Cassandra heeft een open-source versie tot z&’n beschikking. Cassandra wordt onder andere gebruikt door CERN, eBay, GitHub, Instagram, Netflix, Reddit een veel meer.
Cassandra is geschreven is Java. De keuze daarvoor is dat Java veel veiliger gehouden kan worden vergeleken C++ (denk aan buffer overflows). En de prestaties; het duurt wellicht iets langer voordat Java opgestart is in de VM. Het belangrijkste punt wat je moet houden is hier: Java-code wordt continu geoptimaliseerd door de VM, dus in sommige omstandigheden is het zelfs sneller dan C++. Immers C++ blijft onveranderd nadat het eenmaal gecompileerd is.
Installeren
We gaan nu aan de slag met Cassandra op een Debian GNU/Linux server. We beginnen met het installeren van Oracle Java 8 (OpenJDK is ook mogelijk) via command-line:
su root
echo "deb http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main" > /etc/apt/sources.list.d/webupd8team-java.list
echo "deb-src http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main" >> /etc/apt/sources.list.d/webupd8team-java.list
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys EEA14886
apt-get update
apt-get install oracle-java8-installer
Controleer je Java versie: java -version
Nu gaan we Cassandra (v2.2 op dit moment) zelf installeren:
echo "deb http://debian.datastax.com/community stable main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
curl -L http://debian.datastax.com/debian/repo_key | sudo apt-key add -
sudo apt-get update
sudo apt-get install cassandra dsc22
Dat was het! Cassandra is up-and-running.
Configureren
Ik verander mijn cluster naam naar “melroy”. En ik wil mijn data opslaan op een andere schrijf, namelijk: /media/data. Hier heb ik een aparte folder aangemaakt genaamd cassandra. Let erop dat ik de commit log wel op een andere schrijf plaats dan mijn data directory.
Het volgende configuratie bestand moeten we hiervoor aanpassen: sudo nano /etc/cassandra/cassandra.yaml
Met als wijzigen:
cluster_name: "melroy"
listen_address: 127.0.0.1
data_file_directories:
- /media/data/cassandra/data
commitlog_directory: /var/lib/cassandra/commitlog
saved_caches_directory: /media/data/cassandra/saved_caches
Vanaf Cassandra 2.2 en hoger staat Thrift Client (oude protocol) standaard uitgeschakeld. En wordt het nieuwe protocol gebruikt (Native Protocol v3). Het is mogelijk om CQL verbinding op te zetten via poort 9042 (CQL native transport port ).
Herstarten
Helaas startte Cassandra direct op na installatie via apt-get commando. Bij het opstarten van Cassandra leest hij de Gossip items in uit het cassandra.yaml configuratie bestand. Hierdoor staat de cluster naam op “Test Cluster”. Om dit op te lossen veranderen we eerst de systeem database, dit doen we wederom via command-line als volgt:
sudo service cassandra stop
sudo rm -rf /var/lib/cassandra/data/system/*
sudo service cassandra star
Tijdens het opstarten van de Cassandra node, leest hij nu opnieuw de cassandra.yaml bestand in. Zo kijkt hij onder andere naar cluster_name, listen_address, broadcast_address. In mijn voorbeeld staat de cluster naam nu op “melroy”. 😀
Mocht je problemen ondervinden, kun je de logging vinden via: tail -f /var/log/cassandra/system.log
Weather station Pro

In mijn thuis project draait ik op dit moment Cassandra v2.2 Met CQL specificatie versie 3.3. Je kunt dit eenvoudig controleren door het cqlsh commando uit te voeren op command-line, deze toont meteen de versie nummers.
Zoals eerder al uitgelegd was, staat CQL voor Cassandra Query Language, het is een query taal van de Cassandra database. Via deze manier kun je keyspaces en tabellen toevoegen, doorzoeken, verwijderen en veel meer.
Voor de mensen die SQL gewend zijn, dat is vergelijkbaar met SQL door rationele database systemen zoals MySQL.
Voorbeeld
We beginnen met een simpel voorbeeld. We gaan een keyspace aanmaken genaamd “weatherstation”. Ik ga namelijk weer data bijhouden. Een “keystore” is vergelijkbaar met een “database” in bijvoorbeeld MySQL.
Gezien ik maar over een enkele data center beschik kies ik voor SimpleStrategy als class. Meestal kies je voor NetworkTopologyStrategy bij grote netwerken, waarbij het eenvoudiger is om uit te breiden voor meerdere data centers in de toekomst. Ik ga hier niet teveel in detail, in de Cassandra documentatie is er voldoende over te vinden. De volgende CQL query voegt een nieuwe keystore toe:
CREATE KEYSPACE IF NOT EXISTS weatherstation WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 3 };
Alle keystores kun je bekijken via het volgende CQL aanvraag: DESCRIBE keyspaces;
Vervolgens gaan we naar de desbetreffende keystore: USE weatherstation;
Nu gaan we een tabel maken, genaamd: “readings_ts”. De afkorting “ts” staat hier voor timeseries.
CREATE TABLE weatherstation.readings_ts (
weatherstation_id uuid,
date text,
event_time timestamp,
humidity float,
pressure float,
temp_1 float,
temp_2 float,
temp_3 float,
uv_level float,
uv_voltage float,
wind_direction float,
wind_rpm float,
wind_speed float,
PRIMARY KEY ((weatherstation_id, date), event_time)
) WITH CLUSTERING ORDER BY (event_time ASC);
Controleren kan met: DESCRIBE readings_ts;
UUID is een uniek ID, gezien ik maar 1 weerstation heb gebruik ik telkens dezelfde waarde. Timestamp is de unix timestamp. Date is een tekst veld, in mijn geval voer ik het jaar & maand in (yyyy-mm). De rest zijn alle meetdata die ik wil opslaan per keer (10x per seconden bijvoorbeeld), zoals de temperatuur, luchtvochtigheid en meer.
De primary key is in een tabel erg belangrijk. Zeker in Cassandra. Bij het ontwerpen van een database moet je altijd bedenken hoe je uiteindelijk de data wordt opgeslagen en hoe je dit wilt uitlezen. Kortom we hebben veel “inserts” (schrijfacties) en regelmatig ook leesacties van de harde schijf. Zo wil je je bijvoorbeeld de temperatuur weten van de afgelopen dag, week of maand.
Primary key
Alle sleutels in de primary key kunnen gebruikt worden om data uit je tabel te halen. De primary key bestaat uit een partition gedeelte en clustering gedeelte in Cassandra.
Het eerste gedeelte is de “partition key”, deze staan nu nog extra tussen haakjes. Namelijk weatherstation_id en date. De partition key wordt gebruik voor het verdelen van de data binnen het Cassandra netwerk / nodes. Deze partition key MOET voldoende uniek zijn om te voorkomen dat alle data op 1 node terecht komt. Er bestaat tevens een richtlijn die zegt:
het limiet van de aantal rows * columns in 2.000.000.000 per partitie
Het is geen hard-limit, maar wel een goede indicatie. Vandaar dat ik voor een meer unieke partitie-sleutel heb gekozen door er een date veld bij te stoppen. Dit veld bestaat zoals eerder genoemd enkel uit yyyy-mm datum formaat.
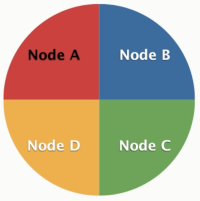
Laten we er vanuit gaan dat we een cluster netwerk hebben van 4 nodes, zoal hierhoven. Node A bevat alle data van “a0-a99” en B van “b0-b99”. Stel we hebben partition key met een waarde “a1” (natuurlijk is het in echt een of andere hash waarde). Deze komt bijvoorbeeld in Node A. Een andere partition key met een waarde “B1”, komt dan in Node B terecht. Op deze manier verspreid je de data over de gehele cluster door gebruik te maken van en partition key. Met een replication factor van 3, wordt dezelfde data ook nog eens op 2 andere nodes opgeslagen (bijv. naast A, ook nog node B en C). Dit voorkomt data verlies bij een crash/ramp, het maakt het tevens mogelijk om nodes te vervangen of te onderhouden.
De “clustering key” zijn alle velden die erna komen, in mijn geval enkel “event_time”. De clustering key is verantwoordelijk voor hoe de data gesorteerd wordt opgeslagen binnen een partitie (= de unieke combinatie van weatherstation_id & date).
Je kunt eventueel gebruik maken van: WITH CLUSTERING ORDER BY (event_time DESC). Standaard wordt alle data oplopend opgeslagen (ASC). Wil je de data juist ophalen in omgekeerde volgorde, aflopend, dan kun je optioneel gebruik maken van clustering order. Op dat moment zijn aflopende queries sneller dan oplopende queries in Cassandra.
Als je de laatste 20 metingen wilt ophalen via de event_time DESC, kun je eenvoudig LIMIT 20 opgeven. Dit geeft nu de laatste rows terug, in plaats van de eerst:
SELECT * FROM weatherstation.readings_ts WHERE weatherstation_id = '1234-abcd' AND date = '2015-09' LIMIT 20;
Voor meer informatie over hoe je Cassandra kunt gebruiken verwijs ik je door naar de Apache Cassandra documentatie.